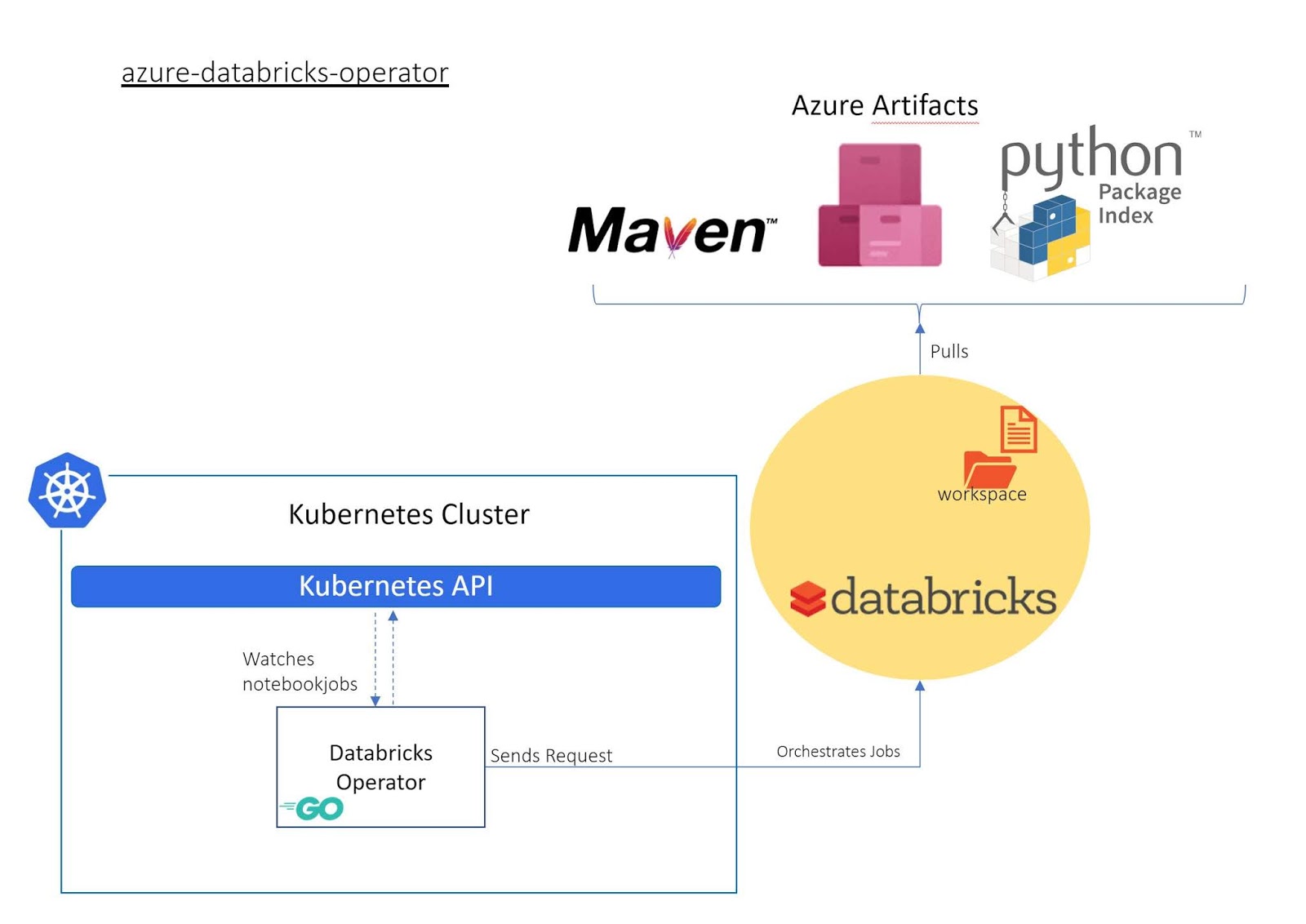
I have been working on Azure Databricks Operator an exciting open-source project to extend Kubernetes API which allows you to run commands on Azure Databricks by using Kubectl and submitting Kubernetes manifest.

Azure databricks is a platform as a service which allows you to create spark cluster in a few minutes. It’s mainly used for large-scale data processing and it’s ideal for ETL, stream processing and machine learning. It provides out of the box connector to connect to data where the data lives. It is integrated with Azure active directory. It also provides interactive workspace which allows data engineers and data scientists to work together, share their work. As a cherry on top, to keep everyone happy it allows to write Spark code in Python, Scala, SQL and R. It also supports Java as well as data science frameworks and libraries including TensorFlow, PyTorch and scikit-learn.
To work with Azure Databricks there are three options

Azure databricks is a platform as a service which allows you to create spark cluster in a few minutes. It’s mainly used for large-scale data processing and it’s ideal for ETL, stream processing and machine learning. It provides out of the box connector to connect to data where the data lives. It is integrated with Azure active directory. It also provides interactive workspace which allows data engineers and data scientists to work together, share their work. As a cherry on top, to keep everyone happy it allows to write Spark code in Python, Scala, SQL and R. It also supports Java as well as data science frameworks and libraries including TensorFlow, PyTorch and scikit-learn.
Key benefits of Azure Databricks in the nutshell
- Large-scale data processing
- Speed
- Scalable to petabytes of data and clusters of thousands of nodes
- Connectors to S3, Azure Blob Storage, Redshift, Kafka
- Security
- Unified platform and Collaboration
- Azure portal
- The Databricks CLI
- Databricks Rest API
If you are in Ops space and looking for ways to automate your process of using azure databricks you would see your options are limited.
If you are using Kubernetes for automating deployment, scaling, and management of your containerized applications then you can easily use Azure Databricks Operator to manage your Azure databricks requests (clusters, fs, groups, jobs, runs, libraries, secrets, ...)
As you can imagine by using manifests instead of writing bash scripts to manage your Azure databricks requests the whole new world of using gitOps, helm charts,... opens up to you.
Key benefits of Azure Databricks Operator
- Easy to use - all the operations can be done by using Kubectl and there is no need to learn or install databricks utils command line and its python dependency
- Security - no need to distribute and give Databricks token to everyone, the databricks token is used by operator
- Support Version control - use git to version control YAML or helm charts which has azure databricks operations (clusters, jobs, …)
- Automation - Replicating azure databricks operations on another databricks workspace by applying same manifests or helm charts
Now let's see it in action
For more details please check out Azure Databricks Operator
If you liked Azure Databricks Operator , I appreciate if you show your support by
- Star and share the Repo within your networks
- Present about Azure databricks operator at your local user group or conference
- Review and raise issue for feature request or bugs
- Assign an issue to yourself and send PR
I have presented the operator at a few local and international conferences and meetups, happy to present it at your event or organisation if it's required
Melbourne Azure nights
Sydney container camp
San Francisco OpenShift gathering
Sydney Google dev
Melbourne Azure nights
Sydney container camp
San Francisco OpenShift gathering
Sydney Google dev
Comments